In our development team at Brightbox, in addition to working on new products and features, we’re continually working on performance optimisations for our various systems and applications. I thought it would be good to quickly share a recent example of the sort of “under the hood” improvements that we work on.
Brightbox Cloud Firewall is a fully distributed firewall system with no single points of failure. This means that whenever a firewall policy is added or modified by a customer via the API, those changes must be propagated across our cloud infrastructure to any relevant network hosts.
Our firewall rule propagation follows an eventually consistent model, that is, when a request to modify a firewall policy is received by our API it is accepted instantly and then rule changes are subsequently distributed across our systems.
For customers with small numbers of Cloud Servers, this happens almost immediately, but until recently, for customers with larger footprints it may have taken several seconds for firewall changes to be applied consistently across all of their cloud servers.
When investigating ways to improve the performance of firewall propagation we realised that, while customers may have hundreds or thousands of cloud servers, they often have a relatively small number of firewall policies. Using this simple fact, we were able to consistently apply a cached version of the firewall rules to all relevant hosts.
The graph below shows a comparison of times taken to propagate firewall changes before and after we optimised rule propagation:
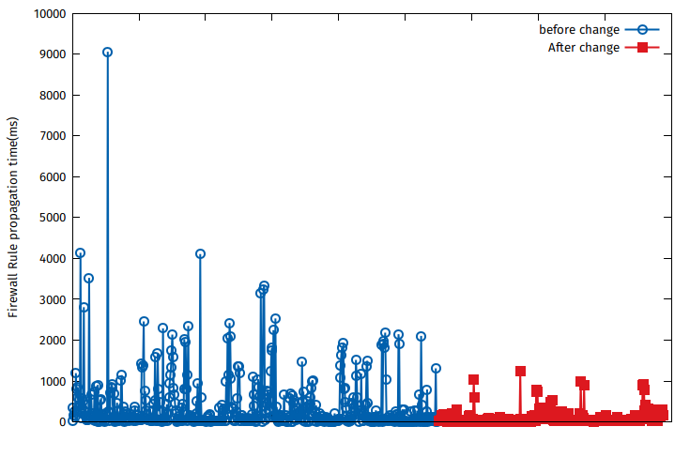
There is still plenty of room for improvement and we are working on additional optimisations in the way we distribute backend changes to underlying hosts. Stay tuned for more updates!
I hope you find this quick peek “under the hood” into our firewall system interesting, please do let me know any questions in the comments below or send us a tweet at @brightbox.